🎧 Our audio samples are available at above Audio Demo site.
🖥️ Source code and model checkpoint will be released after the paper decision.
Diffusion-based generative models have exhibited powerful generative performance in recent years. However, as many attributes exist in the data distribution and owing to several limitations of sharing the model parameters across all levels of the generation process, it remains challenging to control specific styles for each attribute. To address the above problem, this paper presents decoupled denoising diffusion models (DDDMs) with disentangled representations, which can control the style for each attribute in generative models. We apply DDDMs to voice conversion (VC) tasks to address the challenges of disentangling and controlling each speech attribute (e.g., linguistic information, intonation, and timbre). First, we use a self-supervised representation to disentangle the speech representation. Subsequently, the DDDMs are applied to resynthesize the speech from the disentangled representations for denoising with respect to each attribute. Moreover, we also propose the prior mixup for robust voice style transfer, which uses the converted representation of the mixed style as a prior distribution for the diffusion models. The experimental results reveal that our method outperforms publicly available VC models. Furthermore, we show that our method provides robust generative performance regardless of the model size.
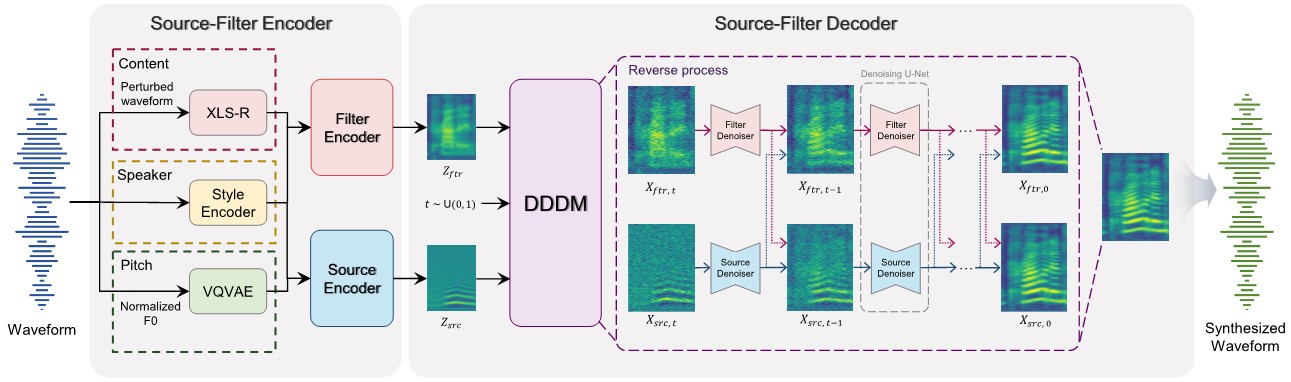
Overall framework of DDDM-VC
Filter Denoiser
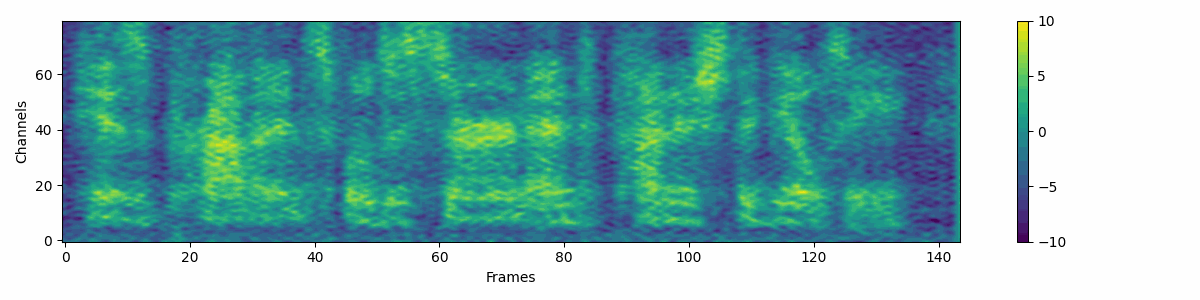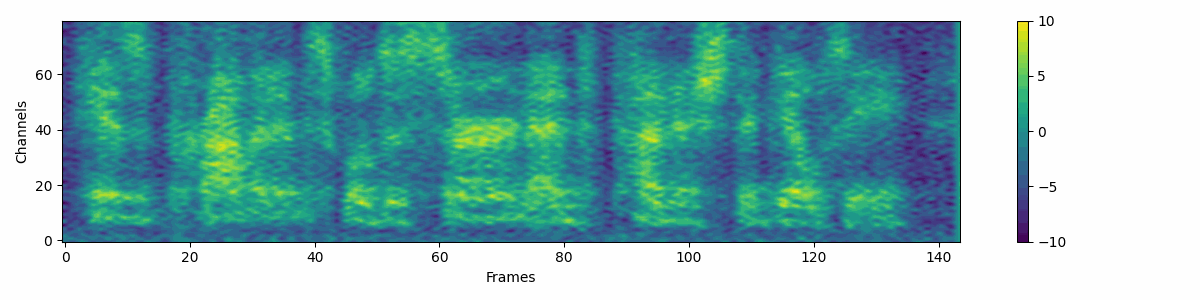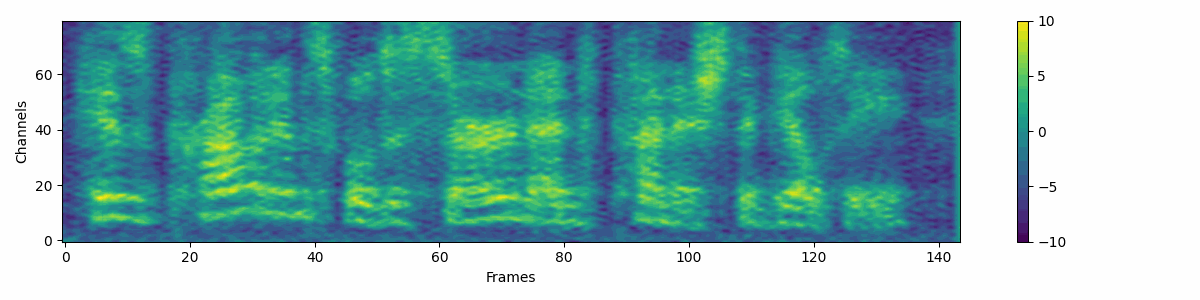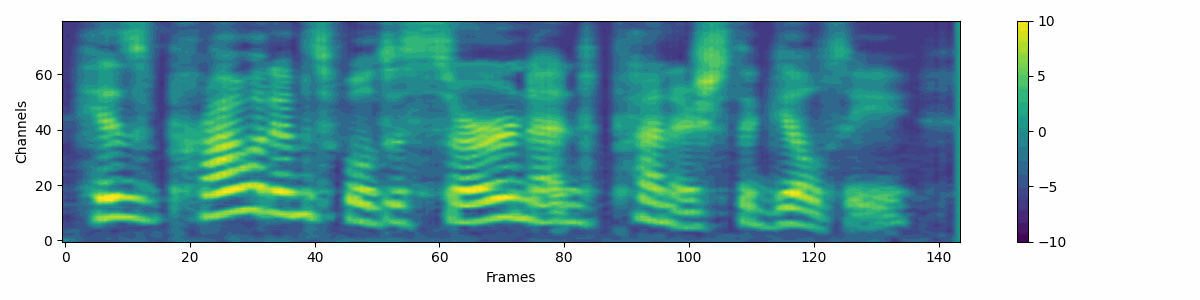
Filter attribute denoising process
Source Denoiser
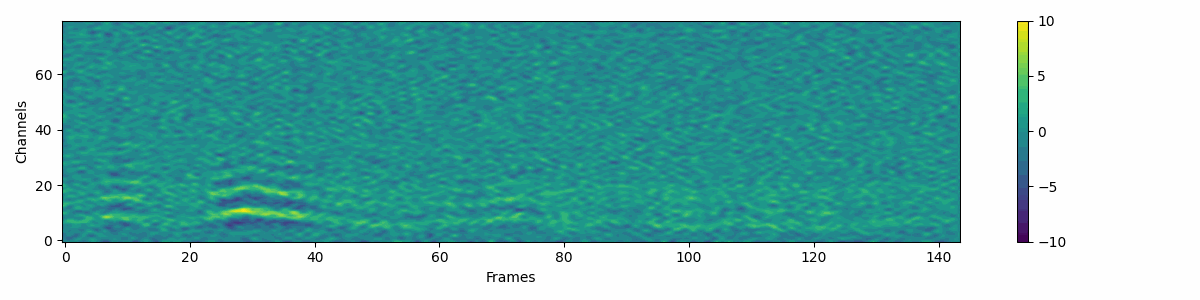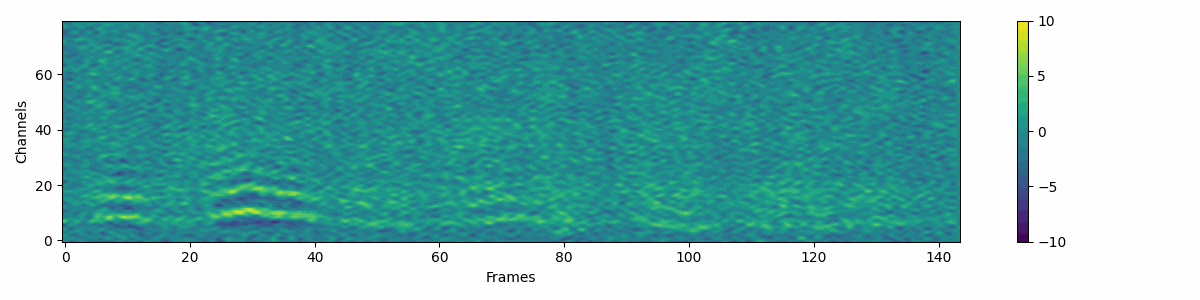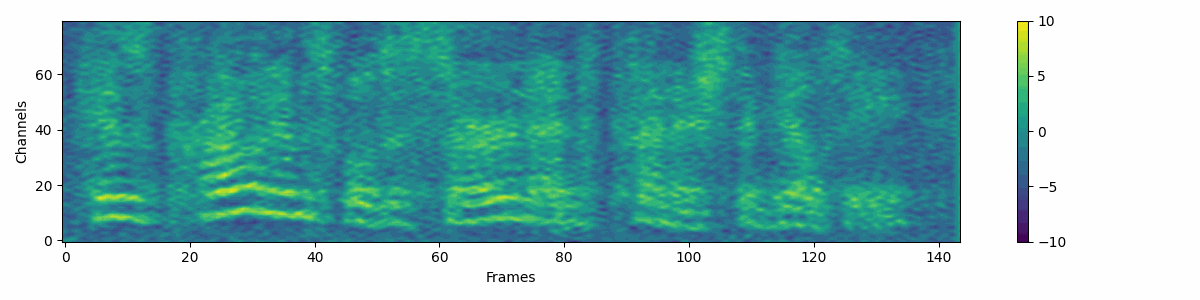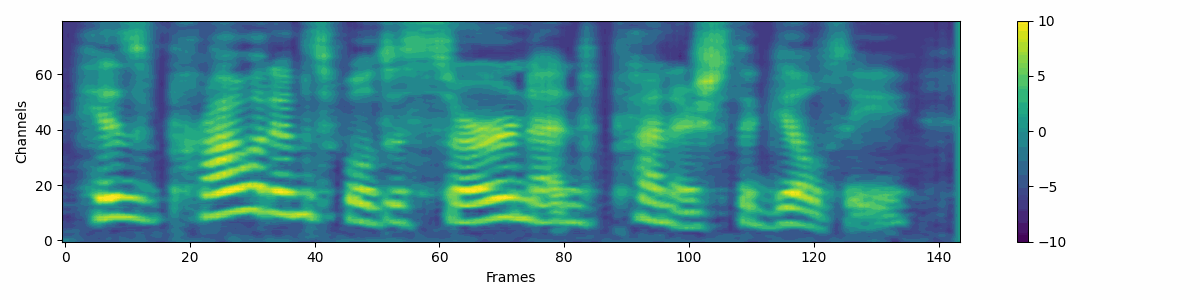
Source attribute denoising process
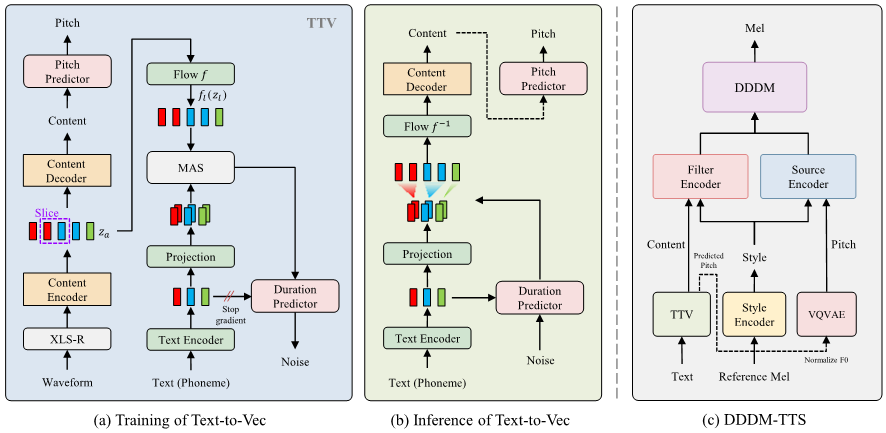
Overall framework of DDDM-TTS
For a practical application, we have experimented with an extension version of DDDM-VC for a text-to-speech system. In DDDM-VC, our goal is to train the model without any text transcripts, and only utilize the self-supervised representation for speech disentanglement. Based on the DDDM-VC, we train the text-to-vec (TTV) model which can generate the self-supervised speech representation (the representation from the middle layer of XLS-R) from the text as a content representation. We jointly train the duration predictor and pitch predictor. The predicted content and pitch representation are fed to DDDM-VC instead of each representation from the waveform to synthesize the speech. Hence, we could synthesize the speech from text by utilizing the pre-trained DDDM-VC.
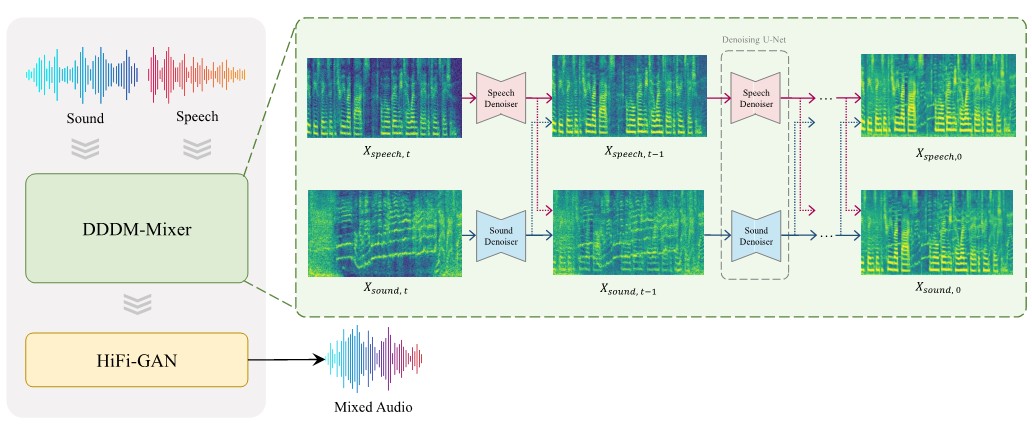
Overall framework of DDDM-Mixer
We extend DDDMs to DDDM-Mixer which leverages multiple denoisers to mix the sound and speech into the mixture of Mel-spectrograms by blending them with the desired balance. While DDDM-VC disentangles a single speech into source and filter attributes for attribute denoisers, DDDM-Mixer treats the mixture of audio as a target audio and disentangles it into sound and speech as attributes. We utilize the data augmentation according to signal-to-noise ratio (SNR) from -5 dB to 25 dB for target audio. DDDM-Mixer utilizes the Mel-spectrogram of each attribute as a prior. We employ two denoisers, both of which remove a single noise in terms of their own attribute (sound and speech). We utilize an SNR dB between sound and speech as conditional information to mix each attribute with a desired ratio. We concatenate the SNR positional embedding with the time positional embedding for the condition. Hence, we could mix the generated sound and speech on the Mel-spectrogram. To verify the effectiveness of the DDDM-Mixer, we compare the augmented audio between vocoded sound and speech and the vocoded audio from mixed Mel-spectrogram. The evaluation results show DDDM-Mixer has better performance than audio augmentation according to SNR between the vocoded sound and speech.